JSTOR (short for Journal Storage) is a digital library that provides access to academic journals, books, and primary sources. It was founded in 1995 by the Andrew W. Mellon Foundation with the goal of creating a digital archive of scholarly literature. JSTOR currently has over 10 million documents in its digital library, and it is used by thousands of academic institutions and libraries around the world.
One of the key features of JSTOR is its use of Digital Object Identifiers (DOIs) to uniquely identify and track each document in the library. DOIs are unique codes that are assigned to each document and allow users to easily locate and cite the document. JSTOR also uses a system called the Data for Research (DFR) platform, which allows researchers to access data on the usage and impact of the documents in the JSTOR library.
The DFR platform is a powerful tool for researchers because it provides detailed information on how often a document has been accessed and cited, as well as other metrics such as the number of times it has been shared on social media. This data can be used to evaluate the impact and importance of a particular document or research study.
In addition to providing access to scholarly literature, JSTOR also offers a range of tools and resources for researchers. These include a citation management tool, which allows users to easily create bibliographies and citations for their research papers, and a text analytics tool, which allows users to analyze the content of documents in the JSTOR library.
Overall, JSTOR is an important resource for researchers and scholars in the academic community. It provides access to a wealth of knowledge and information, and its DFR platform allows researchers to evaluate the impact and importance of individual documents in the library.
Known Quirks of JSTOR/DfR Data
If you have the need for larger data sets then you can contact JSTOR and provide a project description and the number of items needed. Both charts allow for zooming, which is particularly useful for the Year of Publication. There is currently no general solution for this issue. Furthermore, the pages need to be parsed properly: you will run into troubles if you calculate page numbers like 75284 - 42 + 1, in case the number was parsed badly. What format is the data? This is the kind of pattern that calls out for interpretation and is the subject of section 5. Since there might be other ways of specifying pages, jstor does not attempt to parse the pages to integers when importing.
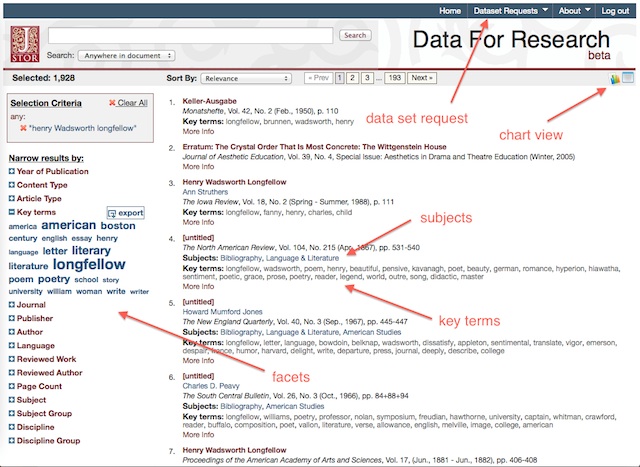
In 1981 Roy Porter and Mikuláš Teich edited a volume called The Enlightenment in National Context, in which contributors examined how the Enlightenment played out differently in different countries. Aufklärung or the French or the Scottish Enlightenment is far lower 110, 169, and 216 documents, respectively. It could well be that these kinds of questions are less likely to appeal to nonspecialists, who may not always see the point or what is at stake in such arguments. The author name is a hyperlink that searches JSTOR for other articles by that author that meet the same search criteria. I have, however, sought to work around this problem by tracking the presence of various influential theorists. But they are all well represented in JSTOR, making data mining one of few options for studying Enlightenment scholarship across multiple disciplines.
This would pose no problem either, we could simply extract all digits via regex and parse as character. Besides this problem, there is actually another issue. Even when results do not seem to depend on sample size or special circumstances, it can still be very hard to make sense of them. Four different ways how references can be specified are known at this time, and all are imported in specific ways to deal this variation. The hyperlink for the subjects in the citation work the same way as the author hyperlink: the result is a search for the same criteria within that subject. Indeed, it would be more likely for interest in specific, separate Enlightenments to exhibit a different pattern of usage since this would indicate that a smaller field of scholars, probably under a common methodological thrust, had adopted a concept. First and foremost, the data about articles and books come from a wide variety of journals and publishers.
Accordingly, they are likely to be less well versed, and possibly less interested, in the more specialized and, particularly, recent scholarship. After downloading several data sets in this manner, then you can combine the data into a single large data set. Key Features DfR is an excellent tool for building data sets to identify previously unknown patterns and relationships among articles. Unfortunately I have neither the time nor the interest to wade through all the data which you could get from DfR in order to find all possible quirks. The place of these theorists is remarkable not only in itself but also in contrast with that of earlier Enlightenment scholars. Are we missing important trends? The point of the historical label is to identify the forest, not to describe the trees. To better comprehend what exactly was occurring during the peak moment of interest in the Enlightenment, I compared it with another three-year interval shortly thereafter 2002—4.
Enlightenment Scholarship by the Numbers: webapi.bu.edu, Dirty Quantification, and the Future of the Lit Review
Scholars writing in this vein concentrate on such questions as What is liberalism? Before requesting a larger data set you will want to work with a smaller set or a sample of the data first in order to verify that the data will meet your research needs. This exercise in quantification thus forces us to consider a somewhat awkward question: should everyone get a vote? And should nonspecialists get a say in the historiographical debates of a particular field? Enlightenment Debates The scholarship on the Enlightenment is particularly well suited as a case study for this data-driven approach. But when we compare more closely related patterns of usage, a narrative may start to emerge. These are primarily arguments about the terms of the argument, and only indirectly about the content of the Enlightenment itself. The following sections discuss the results. This fracturing of the Enlightenment into smaller pieces raises new questions as well. In most cases, the error will go away.
They exhibit some similarities: both terms see an increase in 2006 and a drop-off after 2009. At the same time, a few national Enlightenments do also receive considerable attention, and have done for quite some time well before 1981 in any case: see Fig. This a difficult question to answer, though it may help to consider the effect of time on a scholarly consensus. When you get those messages, wait a few seconds and reload the screen. Page numbers Page numbers are a mess. This vignette tries to list as many as possible, and offer solutions for dealing with them.
The citation title displayed in red is a hyperlink to the full-text of the article. Some internal functions regarding file paths and example files were adapted from the package readr. Unfortunately, sometimes the page is specified like this: v75i2p84. At the bottom of the Charts View screen is an option to Download data for year chart. A little over a third 37. Again, there are a number of possible causes: it might be linked to the popularity of one or more theorists; to the publication of key works; to the emergence of new fields around this topic; or to the redirection of a discipline.
Note: As of 2021, JSTOR has moved changed the way they provide data to a new platform called jstor has not been adapted to this change, and might therefore only be used for legacy data that was optained from the old DfR platform. What is Romanticism or Realism or Modernism? However, if your content is foreign language material then you may want to choose XML. Are book reviews or are research articles more responsible for this change? In singling out this last category of scholarship among other types—the list is not intended to be exhaustive , I do not mean to suggest that defining terms is unimportant. Unfortunately, sometimes the page is specified like this: v75i2p84. . It is also a tricky exercise, which can easily be misleading.
And what is Enlightenment? Unfortunately, it is still too soon to detect the influence of these works through data mining. Data is available in either XML or CSV. For those familiar with the history of the Enlightenment, these numbers are of course not surprising. For example, clicking on James E. Voltaire and Diderot may well have less in common than, say, Diderot and Hume. But after 1991, the trend changes, with both expressions appearing in roughly the same number of documents between 1992 and 2011 120 and 121, respectively. Unfortunately I have neither the time nor the interest to wade through all the data which you could get from DfR in order to find all possible quirks.