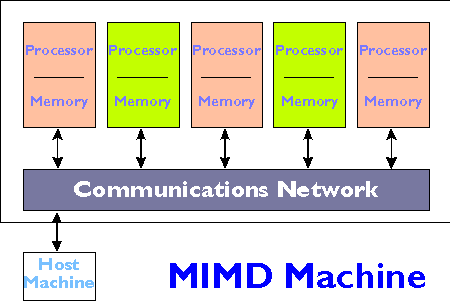
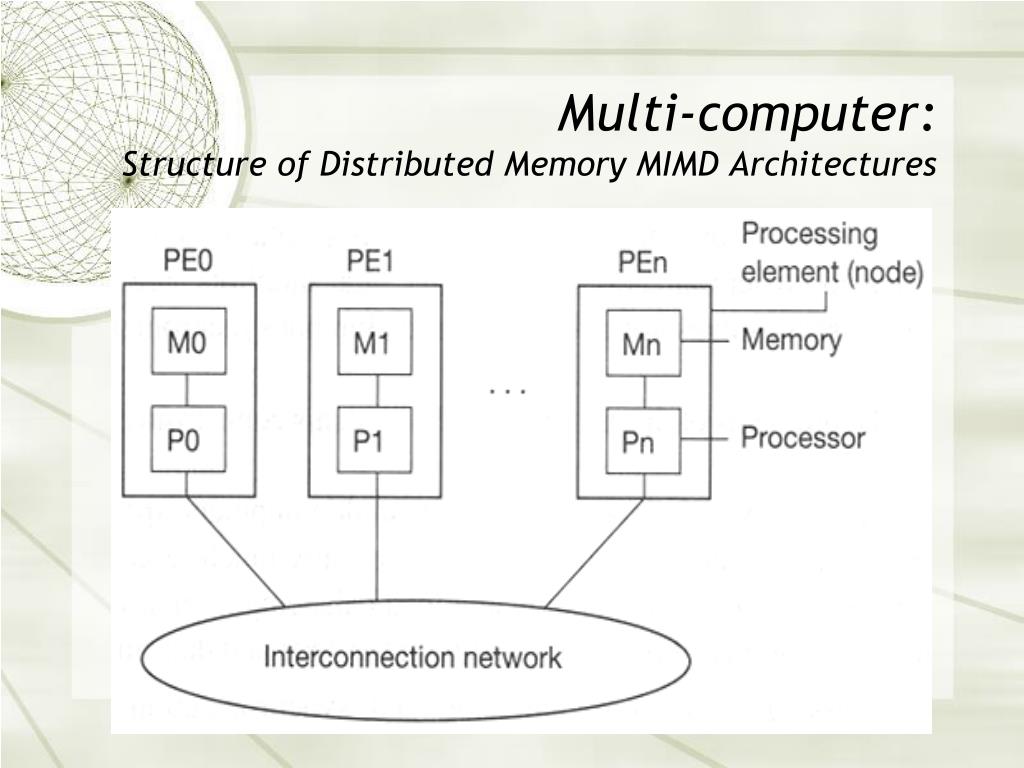
Distributed memory MIMD (Multiple Instruction Multiple Data) architecture is a type of computer system that uses multiple processors that can operate independently to execute different tasks simultaneously. This architecture is characterized by the presence of multiple processors, each with its own memory, and a shared communication network that enables the processors to communicate and coordinate with each other.
One of the key advantages of distributed memory MIMD architecture is its ability to perform parallel processing. With multiple processors working simultaneously, tasks can be completed much faster than they would be in a single-processor system. This makes distributed memory MIMD architecture particularly well-suited for applications that require high levels of computational power, such as scientific simulations, financial modeling, and data analysis.
Another advantage of distributed memory MIMD architecture is its scalability. As the number of processors increases, the system's overall processing power increases as well. This means that a distributed memory MIMD system can be easily upgraded by adding more processors, allowing it to handle increasingly complex tasks.
One of the main challenges in designing a distributed memory MIMD system is ensuring that the processors can communicate effectively with each other. This is typically achieved through the use of a shared communication network, which can be either a bus-based or a network-based system. Bus-based systems are simpler and less expensive, but they are limited in terms of the number of processors that can be connected and the speed at which data can be transferred. Network-based systems, on the other hand, are more complex and expensive, but they are able to support larger numbers of processors and provide faster data transfer speeds.
Despite these challenges, distributed memory MIMD architecture has proven to be a powerful and flexible computing platform, and it has been widely adopted in a variety of applications. It is likely to continue to play a key role in the development of high-performance computing systems in the future.
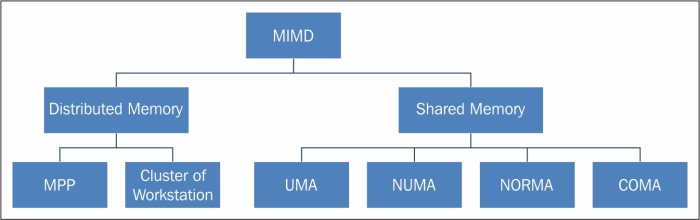
MIMD Architecture
The lower the degree of a node, the better the design for message transmission. A special ownership scheme is applied to maintain cache coherency. It means that whenever a packet travels on the global ring it will reach its destination without delay. This is the separating characteristic between NUMA and CC-NUMA multiprocessors. As such, these machines are the most like those in use now. In NUMA machines, like in multicomputers, the main design issues are the organization of processor nodes, the interconnection network, and the possible techniques to reduce remote memory accesses. The processing nodes of the machine are grouped into shared bus symmetric multiprocessors, called stations.
In these systems, multiple buses compose a grid interconnection network. Buss support communicating between boards. Only after the "partner process" completes its usage of a channel can a sender transmit its message. In the ready stage, the PC is stored in its workspace register, W, and the also stores two Ready lists one for high priority and one for low priority messages. Accordingly, most of the shared memory systems employ cache memories, too. This is provided either by a shared path network that can be allocated to any active component of the machine on a competitive basis or by a number of switches that can be set in different ways according to the connection requirements.
Although the UMA architecture is not suitable for building scalable parallel computers, it is excellent for constructing small-size single bus multiprocessors. Since only one process uses type 3 variables it is sufficient to cache them only for that process. This system also uses a wormhole routing scheme in message distribution. There is great value in this information. Two examples of NUMA machines are the Hector and the Cray T3D multiprocessor. In a deadlock, a subset of the messages the flits, I believe are all blocked at once and are awaiting a free buffer to be released by a message that follows it.
These are connected by bit-parallel local rings which are, in turn, interconnected by a single global ring. This is most frequently used for shared libraries and for Execute in Place. In the case of write transactions the data bus is used together with the address bus, while in a read transaction the data bus can be used by a memory unit to transfer the result of a previous read access. In multicomputers, the reference infinite is replicated in the local memories of the processing elements. The idea behind it is related to the notion in computer science known as the Traveling Salesman problem, the Shortest Path Algorithm from point A to point B or in this case node A to node B is directly linked to the shape that the nodes generate when linked together. It proposes multiple-bus networks with the application of hierarchical cache coherence protocols that are generalized or extended versions of the single bus-based snoopy cache protocol. The address and data are transferred via the bus to the memory controller.
Although the crossbar provides a scalable bandwidth, it is not appropriate constructing large-scale multiprocessors because of the large complexity and high cost of the switches. One type of interconnection network for this type of architecture is a crossbar switching network. If the data has not yet returned from the remote node, the processor is stalled. A further improvement was the replacement of the single shared bus by a more complex multibus or multistage network. A shared memory system is comparatively easy to plan since all processors portion a individual position of informations and the communicating between processors can be every bit fast as memory entrees to a same location.
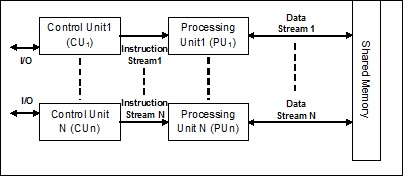
To implement a protocol two components must be defined for the embedded processor of MAGIC: the message type and the executing handler that realises the necessary protocol. The processors execute these instructions by using any accessible data rather than being forced to operate upon a single, shared data stream. The C104 chip uses a deterministic, distributed, minimal routing protocol called interval labeling. The term "multiprocessor" can be confused with the term " Multiprocessor systems are classified according to how processor memory access is handled and whether system processors are of a single type or various ones. He or she then assigns each component part to a dedicated processor.
One type of interconnectedness web for this type of architecture is a crossbar shift web. Programs access what seems to them to be traditional memory. Coherence misses for both machines cost a 100 clock cycles. The main assumption is that shared memory programs generally provide a good locality of reference. Contention is an inherent consequence of sharing and, by introducing an additional shared hardware resource - the shared bus - it became a critical architectural bottleneck. Bottom of Form Multiple Instruction stream Multiple Data stream A computer that can process two or more independent sets of instructions simultaneously on two or more sets of data.
The major topology designs that are mainly used on coarse grain systems include the following: mesh, cube , and fat tree due to their lower implementation costs and has better than average scalability. All can be scaled to the Teraflops level. This means that a message is send from one node to another node that it wants to communicate with to set up a direct connection between them. Assume that capacity misses take 40 cycles when thay are local on the DSM machin and 75 cycles otherwise. Also, adaptive routing types may vary on whether the algorithm they utilize allows for backtracking the message to get out of a nasty situation.
Hardware-based protocols can be further classified into three basic classes depending on the nature of the interconnection network applied in the shared memory system. There is contention among the processors for access to shared memory, so these machines are limited for this reason. Name three methods to avoid a deadlock? Bottom of Form Multiple Instruction watercourse Multiple Data watercourse A computing machine that can treat two or more independent sets of instructions at the same time on two or more sets of informations. Multiple Instruction - Multiple Data MIMD architectures have multiple processors that each execute an independent watercourse sequence of machine instructions. Interconnection network topology has a great influence on message transmission. The network instructions here include SEND, SENDE, SEND2, SEND2E and are used to send messages between processors.
Stanford FLASH The main design issue in the Stanford FLASH project is the efficient combination of directory-based cache coherent shared memory architectures and state-of-the-art message-passing architectures in order to reduce the high hardware overhead of distributed shared memory machines and the high software overhead of multicomputers. The three phases must be executed sequentially. Two such machines are the Encore Multimax of Encore Computer Corporation representing the technology of the late 1980s and the Power Challenge of Silicon Graphics Computing Systems representing the technology of the 1990s. The communication processor is typically a Transputer and the internal hardware supports intensive computations. Shared model provides a virtual address area shared between any or all nodes. In NUMA machines, like in multicomputers, the chief design issues are the organisation of processor nodes, the interconnectedness web, and the possible techniques to cut down distant memory entrees. However, the employment of coherent cache memories as well as multiple buses will significantly increase the expense of building such multiprocessors.