Distributed data processing definition. What does Distributed Data Processing mean? 2022-10-13
Distributed data processing definition Rating:
5,1/10
254
reviews
Distributed data processing refers to the use of multiple computers, or nodes, to perform a shared task. It is a form of parallel computing that involves dividing a large data set or workload across multiple computers, with each computer working on a smaller portion of the data.
One of the main benefits of distributed data processing is the ability to scale up the processing power and speed of a task by adding more computers to the network. This is useful in situations where the amount of data being processed is too large for a single computer to handle, or where the task requires more computational power than a single machine can provide.
Another advantage of distributed data processing is fault tolerance. If one computer in the network fails, the workload can be redistributed among the remaining computers, allowing the task to continue without interruption.
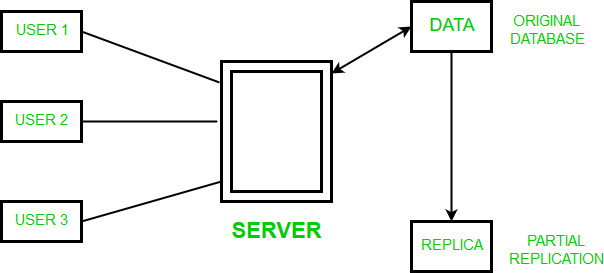
There are several different architectures and approaches used in distributed data processing, including client-server, peer-to-peer, and grid computing. In a client-server architecture, one or more central servers provide resources and services to client computers, which request and receive data from the servers. In a peer-to-peer architecture, all computers in the network are equal and can both provide and request resources and services. In grid computing, a network of computers is used to perform a specific task, such as analyzing data or solving a complex mathematical problem.
Distributed data processing is commonly used in a variety of fields, including scientific research, data analytics, and business intelligence. It is also an essential component of many modern distributed systems, such as cloud computing platforms and distributed databases.
Overall, distributed data processing is a powerful tool for handling large and complex data sets, allowing organizations to harness the power of multiple computers to tackle challenging tasks and make faster, more accurate decisions.
What is Distributed Processing?
Continuous Data Distribution There are also different types of continuous data distributions that are used specifically for continuous data. In essence, this creates a single supercomputer. Figure 6 shows an example of a probability plot. In a distributed database, the system functions even when failures occur, only delivering reduced performance until the issue is resolved. The prerequisite for fragmentation is to make sure that the fragments can later be reconstructed into the original relation without losing data. The bar goes up to three, so there are three trees that are between 60 and 65 feet. The box portion represents the middle 50% of the data.
Lesson Summary Data distributions are used to organize and display information about a set of collected data. Straightforward as this sounds, it requires careful planning. When performing individual processes nodes of a distributed system can exchange information through communication channels in order to process data or obtain the results of analysis of mutual interest to them. We can also see that ratings were provided by fifty customers, one dot for each customer. As this theory has largely proven correct over the last four decades, engineering strategies like distributed processing also have added to the speed of logical devices for some amazing advances in the ability of computers to perform functional tasks.
In particular, the presentation layer contains detailed information about the database structure. How Distributed Processing Can Turbocharge Your Post-Production Workflow There are several benefits to working with a distributed processing system in post-production, given that it can speed up your entire workflow at every point in which time-intensive computing tasks are involved. The result is an increase in response time, especially with a lot of queries. The dots tell us the frequency, or rate of occurrence, of customers who gave each rating. At this stage of the process, machine learning or artificial intelligence algorithms will make sense of the data, preparing to output useful information.
For example, students can theoretically score an infinite number of final exam grades on a scale of 0 to 100. By counting the number of tally marks, we can see that there were thirteen occurrences of paint chipping, three occurrences of bubbles, etc. Continuous data includes variables that could have an infinite number of values on a scale. One of the major motivations behind the use of database systems is the desire to integration the operation data of an enterprise and to provide centralized, thus controlled access to that data. Discrete data includes variables that have specific values that cannot have scores between those values. In other words, it counts how many times an event happens. Google is opening a virtual window into the secretive data centers where an intricate maze of computers process Internet search requests, show YouTube video clips and distribute email for millions of people.
Distributed Data Processing Definition, Find the Latest Article
The key to this understanding is the realization that the most important objective of the database technology is integration, not centralization. Common sources of raw data include the stock market and financial data, social media, websites, apps, emails, and other online activities. Figure 1 is an example of a histogram. This require research in distributed processing as defined earlier as well as in parallel processing. In the new IT development process, data center construction has entered the era of cloud computing, enterprise IT storage environment can not be simple. All three layers, including the database processor, almost always run on the same computer.
What is Data Processing? The Ultimate Beginner's Guide
In the past, MapReduce was mainly used to solve unstructured data such as log file analysis, Internet click Stream, Internet index, machine learning, financial analysis, scientific simulation, image storage and matrix calculation. One fundamental question that needs to be asked is: Distributed is one thing that might be distributed is that processing logic. This means the ease of connecting additional users and resources to it. Discrete data and continuous data involve different types of variables that are associated with different types of distributions. By clearly defining the relevant concepts of large data, enterprises can plan their own data system correctly, and locate the traditional technology and new technical methods appropriately. Many modern processors involve a multi-core design, such as a quad-core design pioneered by companies like Intel, where four separate processors offer extremely high speeds for program execution and logic.
What Is a Distributed Database? {Features, Benefits & Drawbacks}
Each dot represents one value in the set of data. One of the major motivations behind the use of database systems is the desire to integrate the operation data of an enterprise and to provide centralized, thus controlled access to that data. There are several types of data distributions. However the physical distribution of data is very important. When Hadoop enters the enterprise, it must face the problem of how to address and respond to the traditional and mature it information architecture. Example of a box plot While box plots provide useful statistical information about a data set, they do not provide the number or frequency of values like histograms or dot plots do. He has a borderline fanatical interest in STEM, and has been published in TES, the Daily Telegraph, SecEd magazine and more.
What Is Distributed Processing and How Does It Work?
Any changes made on one site must be recorded on other sites, or else inconsistencies occur. Figure 5: Frame a Distribution of quantization errors for sky vs quantization errors for load for true PType 5 data black crosses and the simulated processing orange crosses. Most often the details of these tasks—for example, the priority of the job in the queue or which available machines to make use of on the network—can be set up once and then simply selected per job and executed in the most optimal fashion. Figure 2 is an example of a box plot. Data input Next up: data input.